Workshop
Info
| Time | October 17, 2021 |
| Venue | ICCV, virtual |
| Challenge opens | July 1st, 2021 |
| Challenge deadline | October 8th, 2021 |
| Technical report deadline | October 8th, 2021 |
| Recordings | Will be avalilbe after the workshop! |
In conjuction with the International Conference on Computer Vision (ICCV) 2021
| Time | October 17, 2021 |
| Venue | ICCV, virtual |
| Challenge opens | July 1st, 2021 |
| Challenge deadline | October 8th, 2021 |
| Technical report deadline | October 8th, 2021 |
| Recordings | Will be avalilbe after the workshop! |
| Time | Title | Speaker |
|---|---|---|
| 9:00-9:20 am | Workshop introduction | Organizers |
| 9:20-9:50 am | Talk 1 | Hildegard Kuehne |
| 9:50-10:20 am | Talk 2 | David Held |
| 10:20-10:35 am | Coffee break | - |
| 10:35-11:20 am | Video challenge session | Haotian Zhang, Jincheng Lu, Yizhou Wang |
| 11:20-11:35 am | Video + depth challenge session | Xiangtai Li |
| 11:35-11:50 am | LiDAR challenge session | Rodrigo Marcuzzi |
| 11:50-1:00 pm | Lunch/Dinner Break | - |
| 1:00-1:30 pm | Talk 3 | Charles Ruizhongtai Qi |
| 1:30-2:00 pm | Talk 4 | Katerina Fragkiadaki |
| 2:00-2:30 pm | Talk 5 | Deva Ramanan |
| 2:30-2:50 pm | Break | - |
| 2:50-3:20 pm | Talk 6 | Alexander Kirillov |
| 3:20-3:50 pm | Talk 7 | Philipp Krähenbühl |
| 3:50-4:10 pm | Break | - |
| 4:10-5:00 pm | Round table discussion | All speakers |
| 5:00 pm | Closing remarks | Organizers |
For the 6th edition of our Benchmarking Multi-Target Tracking workshop, we are planning to take multi-object tracking and segmentation to the next level. In this edition, we will organize three challenging competitions, for which we require to assign semantic classes and track identities to all pixels in a video or 3D points based either on a monocular video or a LiDAR stream.
 For this track we extended two existing datasets (KITTI and MOTChallenge) with dense, pixel-precise labels in both spatial and temporal domain: KITTI-STEP and MOTChallenge-STEP. For MOTChallenge-STEP, we have extended the instance-level annotations of two training and two test sequences of MOTChallenge-MOTS labels and 21 training and 29 test sequences of KITTI-MOTS labels. For more information we refer to our recent paper. The task will be to assign a semantic and unique instance label to every pixel of the video.
For this track we extended two existing datasets (KITTI and MOTChallenge) with dense, pixel-precise labels in both spatial and temporal domain: KITTI-STEP and MOTChallenge-STEP. For MOTChallenge-STEP, we have extended the instance-level annotations of two training and two test sequences of MOTChallenge-MOTS labels and 21 training and 29 test sequences of KITTI-MOTS labels. For more information we refer to our recent paper. The task will be to assign a semantic and unique instance label to every pixel of the video.
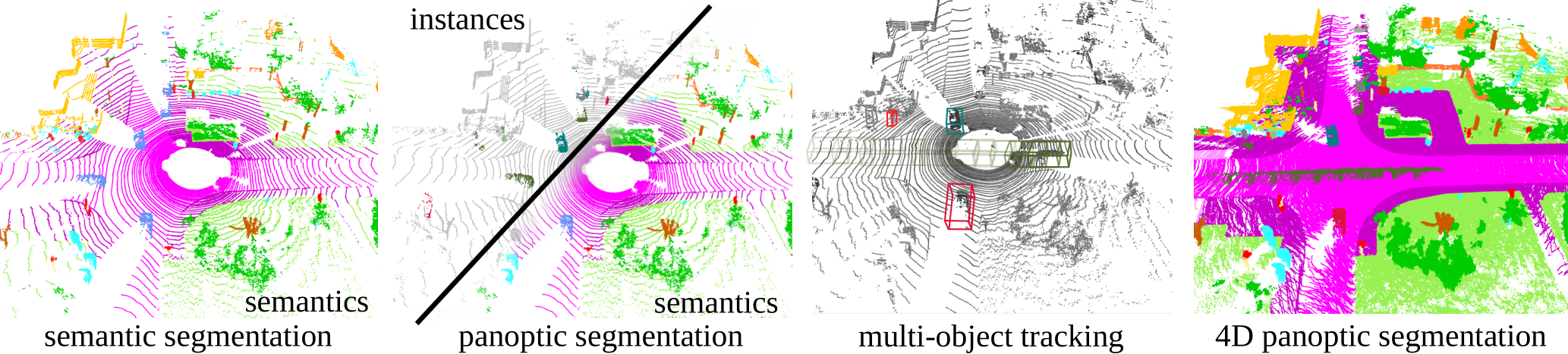 This challenge will be based on the SemanticKITTI dataset, introduced in the context of LiDAR semantic segmentation and panoptic segmentation.
The dataset is densely labeled in the spatial and temporal domain, which makes it a perfect test-bed for our 4D panoptic LiDAR segmentation challenge, as introduced in our recent paper on 4D Panoptic LiDAR segmentation. The task will be to assign a semantic and unique instance label to every 3D LiDAR point.
This challenge will be based on the SemanticKITTI dataset, introduced in the context of LiDAR semantic segmentation and panoptic segmentation.
The dataset is densely labeled in the spatial and temporal domain, which makes it a perfect test-bed for our 4D panoptic LiDAR segmentation challenge, as introduced in our recent paper on 4D Panoptic LiDAR segmentation. The task will be to assign a semantic and unique instance label to every 3D LiDAR point.
 This track will be based on the recently introduced SemanticKITTI-DVPS dataset, that augments LiDAR-based SemanticKITTI dataset with pixel-precise semantic and instance labels of images, derived from LiDAR labels in a semi-automated manner, providing semantic and depth labels needed for evaluation of joint video panoptic segmentation and monocular depth estimation. In addition to assigning semantic and instance labels, this track requires a depth estimate for every pixel.
This track will be based on the recently introduced SemanticKITTI-DVPS dataset, that augments LiDAR-based SemanticKITTI dataset with pixel-precise semantic and instance labels of images, derived from LiDAR labels in a semi-automated manner, providing semantic and depth labels needed for evaluation of joint video panoptic segmentation and monocular depth estimation. In addition to assigning semantic and instance labels, this track requires a depth estimate for every pixel.

Aljoša Ošep (TUM)

Mark Weber (TUM)

Patrick Dendorfer (TUM)

Jens Behley (Uni Bonn)

Cyrill Stachniss (Uni Bonn)

Andreas Geiger (MPI/Tübingen)

Jun Xie (Google)

Siyuan Qiao (JHU)

Daniel Cremers (TUM)

Liang-Chieh Chen (Google)

Laura Leal-Taixé (TUM)





We thank the sponsor of this workshop.






